형태소 분석기라는 것은 기본적으로 많은 분석과정( 코드변환, 사전 탐색, 원형 복원, 색인어 추출등)을 거치기 때문에 그리 빠른 프로그램은 아니다. 그렇다고 분석 과정을 단순화 시키면 분석결과의 질이 떨어지는 문제가 발생하기 때문에 그렇게 하기도 어렵다.
기본적으로 빠른 속도가 아니기 때문에 real time의 서비스에 형태소 분석기를 직접 호출해서 사용하기는 상당한 어려움이 따르는게 현실이다. 일반적으로 이런 어려움을 극복하기 위해서 사용하는 것이 전처리인데 검색엔진에서 색인텀을 미리 추출하여 역색인을 만드는 것도 전처리라고 할 수 있다.
색인을 만드는 과정에 대해서는 많은 관련 자료가 있으니 생략하고, 색인 과정을 형태소 분석기를 호출해서 색인어를 추출하는 과정과 추출된 색인어를 역색인으로 만들고 파일에 최종 기록하는 과정까지 총 2가지 과정으로 나누었을때
일반인들은 물론 하물며 검색엔진을 개발하는 사람들 중에도 형태소 분석기의 분석 속도를 문제 삼는 경우가 종종있다.
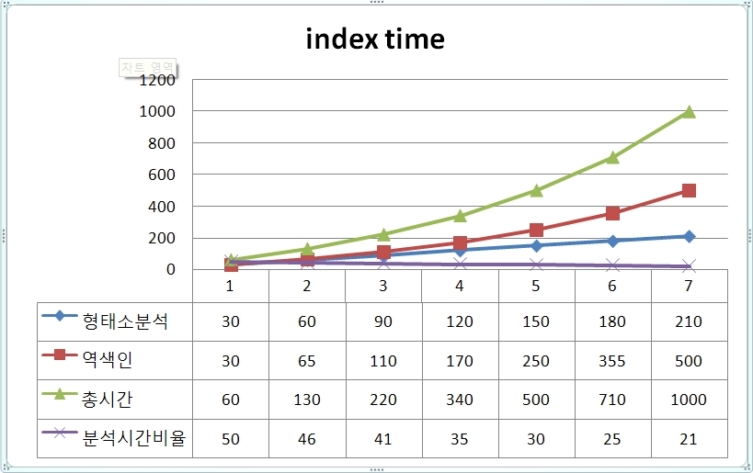
아래 그래프를 보면
형태소 분석 시간은 상수시간이다. 즉 1기가 분석할때 30분이면 10기가 분석할때는 10*30분의 시간이 걸린다는 의미이다.
그러나 역색인을 만드는 것은 1기가에 대해서 30분이 소요되었다면 10기가일때는 (10*(30+a))만큼의 시간이 걸린다.
문서가 대용량일수록 전체 색인시간에서 형태소 분석 시간이 차지하는 비율은 점점 낮아진다는 의미이다.
문서가 크지 않다면 형태소 분석 시간이 전체 색인 시간의 50%까지 육박할수도 있지만, 보통 작은 문서에 대해서 색인을 할때 속도 문제가 발생하지 않는다고 봤을때 문서가 커지면 전체 색인 시간중 형태소 분석이 차지 하는 비중은 오히려 더욱 낮아진다.